复习
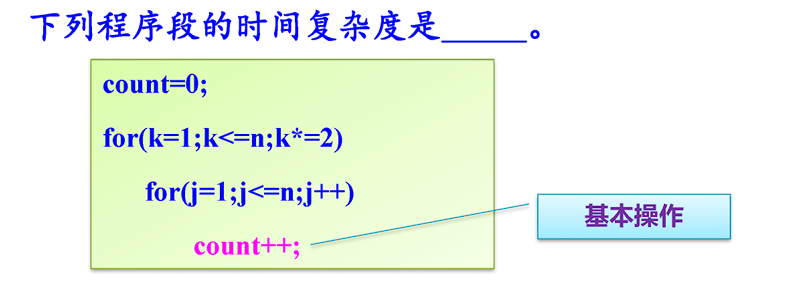
各个循环次数相乘,内层为n,外层为log2n,所以答案是nlog2n
线性表的类型定义 线性表是n个类型相同 的数据元素的有限序列
存在唯一的第一元素/最后元素,除第一元素外,其他元素均有唯一后继,除最后元素外,其他元素都有唯一前驱
顺序线性表的插入操作算法 给三个参数,一个是sqlist类线性表地址&L,一个整数i代表要插入的位置,一个类型e代表要插入的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 Status ListInsert (sqlist &L,int i,elementtype e) { if (L.lenth>=L.listsize); newbase = (elemtype*)realloc (L.elem,(L.listsize+LISTINCERASEMENT)*sizeof (elemtype)); if (!newbase) L.elem = newbase; listsize +=LISTINCREASEMENT; for (j=L.lenth-1 ; j>=i-1 ,--j) { L.elem[j+1 ]=L.elem[j]; } L.elem[i-1 ]=e; L.lenth++; elemtype *q =&L.elem[L.lenth-1 ] for (int j = L.lenth-1 ; j>i-1 ;--j) { *(q+1 ) =*q; q--; } elmtype *p = &(L.elem[i-1 ]); for (elemtype *q =&L.elem[L.lenth-1 ]; q>=p;--q) { *(q+1 ) =*q; } elmtype *p = &(L.elem[i-1 ]); *p =e; ++ L.lenth; }
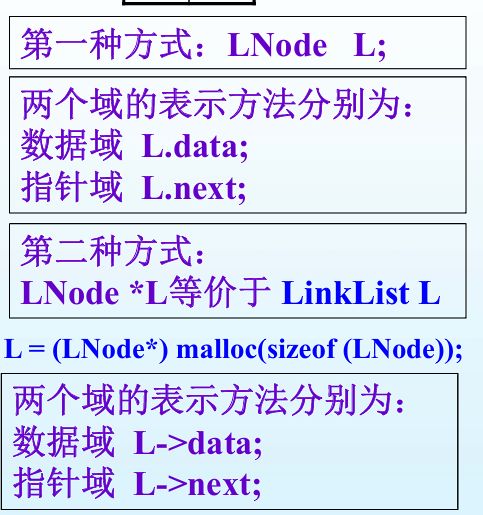
单链表 1 2 3 4 5 6 7 8 9 typedef struct LNode { ElemType data; struct LNode *next //指针域 }LNode ,*LinkList //LNode 是别名,*LinkList 是指向该结构体的指针类型别名 // LNode L 和 *LinkList L 不等价,LNode *L 和 LinkList L 等价 // typedf 定义的是类型名,不要和变量混为一谈
当然,L->data 也可以写为 (*L).data
构造一个空的带头结点的线性表L (切记加L要加&符号)
1 2 3 4 5 6 7 8 9 10 11 LinkList L; void linkinit (LinkList &L) { L = (Lnode*)malloc (sizeof (Lnode)); L->next = NULL ; }
先不考虑结构体相关的东西,而是考虑指针变量最简单的情况,在函数外定义一个int a,要想把int a传入给函数并且让函数能够改变他,就要传入&a,这样函数内的指针变量就能跟就这个地址对他修改,这个过程中,加&符号是为了让函数内部的指针变量读取到他的地址,从而对它进行修改
对于linklist l,虽然它本身已经是一个结构体指针变量了,他已经表示一个地址,但是如果直接把他传进函数,实际上传入的是这个地址变量的副本,虽然形参和实参的具体值是一样的(即l所代表的地址),但是只有这个地址是没有办法进行操作的,因为对于一个结点来说,之所以使用结构体指针变量,目的是为了能让别的结构体指针变量的指针域能指向自己,从而对自己进行操作,而不是主要目的是为了去操作别的结点,因为指向别的节点使用它的指针域完成的,而不是结构体指针自身去指,因此如果不加&符号,虽然指向的东西没有改变(但这就像刚才说的,他指向的东西没有意义,因为我们使用他内部的指针域来指向下一个节点,而不是用它自身),但是传入的实际上是一个指针的副本,他指向的东西不变,但在函数外别的东西就没法指向副本了,这是没有意义的,因此要加&符号,传入指针的指针,让指针能指向结构体指针
简单来说, 之所以定义LinkList为指针类型,是为了能让他被赋值给其他结构体指针变量内部的 指针域 ,从而连起来
判断是否为空 1 2 3 4 5 6 7 int LinkEmpty (LinkList L) { if (L->next==NULL ) return 1 ; else return 0 ; }
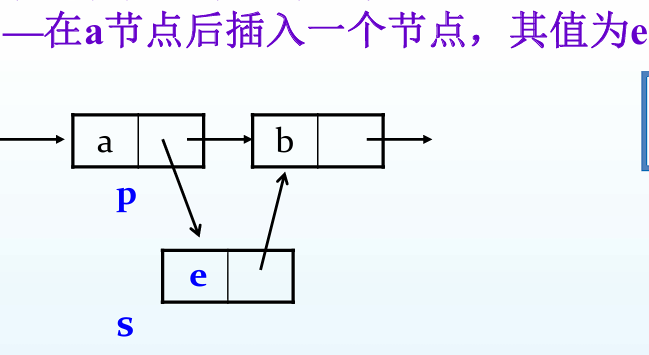
插入元素
1 2 3 4 LinkList sForE = (Lnode*)malloc (sizeof (Lnode)); sForE->data = e; sForE->next = pre->next; pre-next -> sForE
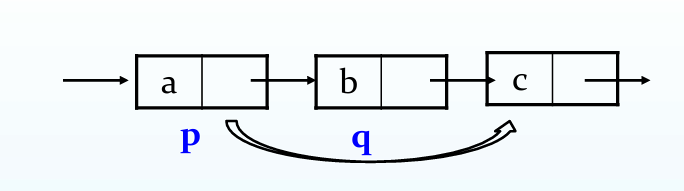
删除元素
1 2 3 4 5 delet = pre->next; pre -> next = delet ->next; free (delete);
取得元素 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 GetElem(linkList L; int i; ElemType *e) { SearchPoint = L -> next; for (int j = 1 ; j<=i; ++j) { if (SearchPoint->next == NULL ) return ERROR; SearchPoint = SearchPoint -> next; if (SearchPoint->next == NULL ) return ERROR; } *e = SearchPoint -> data; return OK; }
循环链表
单链表最后一个结点的指针域没有利用,如果使其指向头指针(头节点),则首尾构成一个链表,称作循环链表
双向链表
一个链表的每个结点都有两个指针域,一个指针指向其前驱节点,另一个指针指向其后继节点
1 2 3 4 5 6 typrdef struct DuLNode { elemtype data; struct DuLNode *pre struct DuLNode *next }DuLNode ,*DuLinkList ;
p->pre->next 和 p->next->pre 都是p自身
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 Status LinkInsert_Dul (DuLinkList&L,int i elemtype e) { DuLinkList PointForE; if (!(point=(GetElemPoint_dul(L,i)))) return ERROR; if (!(PointForE = (DulLinkList*)malloc (sizeof (DulNode)))); return ERROR; PointForE -> next = point; PointForE -> pre = point -> pre; point -> pre -> next = PointForE; point -> pre = point; PointForE -> data = e; return OK; }
1 2 3 4 5 6 7 8 9 10 Status LinkDelete_Dul (DuLinkList&L,int i) { while (!(p=(GetElemPoint_dul(L,i)))) return ERROR; p->pre->next = p->next; p->next->pre = p->pre; free (p); return OK; }
一元多项式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 typedef struct ploy { float factor; int power; struct ploy *next ; }ploy,*ployPoint; Status PloyAdd (ployPoint *a1, ployPoint *a2) { int a1_Maxpower = getMaxPower(a1); int a2_Maxpower = getMaxPower(a2); int a3_Power = Max(a1,a2); a1 = a1 ->next; a2 = a2 ->next; for (int i = 0 ;i<=a3_power;i++) { if (a2->power==a1->power) { a3->power = a1 -> power; a3->factor = a1->factor + a2->factor; a1 = a1->next; a2 = a2->next; } else if (a2->power<a1->power) { a3->power = a2 -> power; a3->factor = a2 -> power; a2 = a2->next; } else { a3 -> power = a1 -> power; a3 -> factor = a1 -> factor; a1 = a1->next; } a3 = a3->next; } }